就为这一个简单的 Bug,我搭上了整整一个工作日
上午9:41,客户群如定了闹钟般发来一条消息提醒。点开闪烁的群消息,“@我 张工,这个问题也请看下,今天发生的频率比较高”。正准备按计划开发需求的我,顿时被按下了暂停键。一句“好的,我看下”,我怎么也没想到直到18:01我才最终修复了它,而且修复方式非常“戏剧化”,特此记录下整个过程。
问题背景
在叙述之前,我先交代一些背景,如果你有兴趣,可以试着代入一下,看看是否能“入戏”一些。
人员背景: 10月27,也就是两周前,我所在部门发起了近 3 年内的第 5 轮“友好分手”。
我所在的 AI 通用项目组整体被裁,包括技术经理在内(甚至包括我在本公司的“第 5 任饭搭子”!)全都在 10月31 say bye。
10月31,成都 Base、北京 Base 都各自吃完了散伙饭,散场时,北京深秋夜晚的寒风似乎总往眼里吹。
是的,应该感谢部门领导的信任,我被“暂时留下了”。
项目背景: 与此同时,我被分派到项目 B 中。
经过 2.5 天熟悉及交接和 2 天新需求及 Bug 修复支援(交接同事协助),我从“零”接手了项目 B 中被“选中”的两位成都同事,耗时近半年打磨的 AI 智能体模块,且 12 月中旬前就要上线生产了。
为什么强调从“零”呢?因为主力同事 A,一直在自己本地 4060 机器上运行的全套开发环境也一并被带走了。
仅有的测试环境被客户直接用于模拟测试,所有修复及更新工作必须在每天17:30后才能进行。我向部门领导反馈了这一问题,想多争取点排期时间和资源,领导一句“不行就把它买下来,邮过来”,我只能微笑闭嘴。
就这样,在焦虑“工作会第一次掉地上?”、“这次一定是裁到动脉了!”、“要给客户看降本增[笑]?”的交接过程中,在新需求和 Bug 修复的多重压力下,挺过了一周。
问题背景: 在测试环境中,基于 K8s 部署的 Collabora Online 在线编辑器在预览文档时频繁出现“请稍等”提示和连接断开的问题。
恰逢交接后的第二周,即本周,客户需要随时可能向他的领导进行功能演示,因此这类影响演示效果的 Bug 必须优先解决。
不er,“补刀的”这位鸽们。为什么早发现了,不狠狠“蹂躏”我的“前任们”?非要等着“宠我”吗?
说实话,这个功能我到现在都还没用过,这个组件也从未接触过。虽然进行了交接,但连核心部分都只是大概过的,更别说这些细枝末节了,只能在处理需求和修复 Bug 的同时逐步熟悉。
快速确认
遇到这类在线编辑器问题,我首先思考的是:这个问题,它是不是应该由我这个后端来解决?
立马私信前端大佬(还好,这个模块的前端开发(成都 Base)也被“留下了”,目前他比我更熟悉业务流程),拉会,在测试环境一起复现了下,F12 看了下接口调用,主要是有个 websocket 请求频繁 close: docdisconnected,粗略问了下此功能的技术实现方式。
前端大佬:“我主要是嵌入了一个链接,其他内容都是后端处理的。”
确认结束,问题存在,由我修复。
收集信息
结束会议,我立即登录测试环境的 K8s,同时开启智能体服务和 Collabora 服务的日志监控,然后再次复现问题,下载日志开始逐行分析。
智能体服务关键日志如下:大约每 10 秒就会断开一次连接。
2025-11-12 10:11:45.633 INFO 7 ... : 目标服务器连接建立,目标会话ID: 3ea3722a-1d4e-e81b-f884-9393949fb362, 客户端会话ID: 4279d495-b4a2-0c41-e91a-f6fd12f613b3
2025-11-12 10:11:45.635 INFO 7 ... : WebSocket代理连接建立成功,客户端会话ID: 4279d495-b4a2-0c41-e91a-f6fd12f613b3, 目标会话ID: 3ea3722a-1d4e-e81b-f884-9393949fb362
2025-11-12 10:11:55.113 INFO 7 ... : 目标服务器连接关闭,目标会话ID: 3ea3722a-1d4e-e81b-f884-9393949fb362, 关闭状态: CloseStatus[code=1001, reason=docdisconnected]
2025-11-12 10:12:15.635 WARN 7 ... : 会话已关闭,停止心跳,会话ID: 4279d495-b4a2-0c41-e91a-f6fd12f613b3Collabora 服务关键日志如下:
Servers should not send pongs, only clients
Unassociated Kit (88132) disconnected unexpectedly问题观察到了,怎么解决?留言问下“前任”大佬,问问看有没有遇到过这个情况。(由于交接较急,大佬说有问题随时问。大佬有职业道德,我个人礼貌来讲,也尽量不打扰。不过 15 号发工资前,大佬应该都能联系上)
大佬很快回复:
之前解决过,添加了心跳机制。当时在本地测试是没有问题了但结合日志后,大佬觉得可能和测试环境网络有关,也给了两个修复建议:缩短心跳的时间、减少转发中间层(被我首先 Pass,如非必要尽量不大动)。
梳理代码
经过简短沟通,我初步算是有了一些线索方向。接下来,我开始结合接口请求信息,梳理后端相关接口以及 websocket 的处理逻辑。
关键流程: 前端通过 websocket 连接到智能体服务,智能体服务在处理请求时通过 WebSocketClient 将请求转发到 Collabora 服务。
测试环境这个流程,确实是稍显“周折”:

通过分析收集到的智能体服务日志和相关代码,我确定问题出在向 Collabora 服务转发请求的过程中 - 代理连接会频繁中断,大约每 10 秒就会断开一次转发会话。
Q:为什么不让前端直接连接 Collabora 服务?
A:主要是涉及一些定制化调整(具体我也没看),以及 Collabora 资源转发。Q:心跳机制是怎么回事?
A:说是为了解决此问题而增加的,主要作用就是定时和 Collabora 维持通信,直到会话关闭。
默认是 30 秒一次,我结合日志中断频率,改为了 5 秒一次。此时,我们热心的前端大佬,也给我发来了一些 GPT 回答,大意是修改 Nginx websocket 请求超时时间之类的,但从我梳理的情况看,觉得 Nginx 实在没理由影响到后端转发。
当然,我也拿着日志的关键词和一些设想,检索过搜索引擎、尝试各知名 AI 及 AI Builder、检索 Collabora GitHub Issue,但都没什么太好的头绪,所以我连 Issue 都没想好如何去提,干脆也没麻烦人家。
搭建本地环境
先改改心跳时间试试吧。改完后,想测试下,奈何没有环境,于是在开发环境搭了一套服务,具体的搭建过程可以参考 《Docker 安装 Collabora Online》。
经过一番研究,在本地跑通了,没想到竟然无法复现。
不是改心跳的事,没改也无法复现。
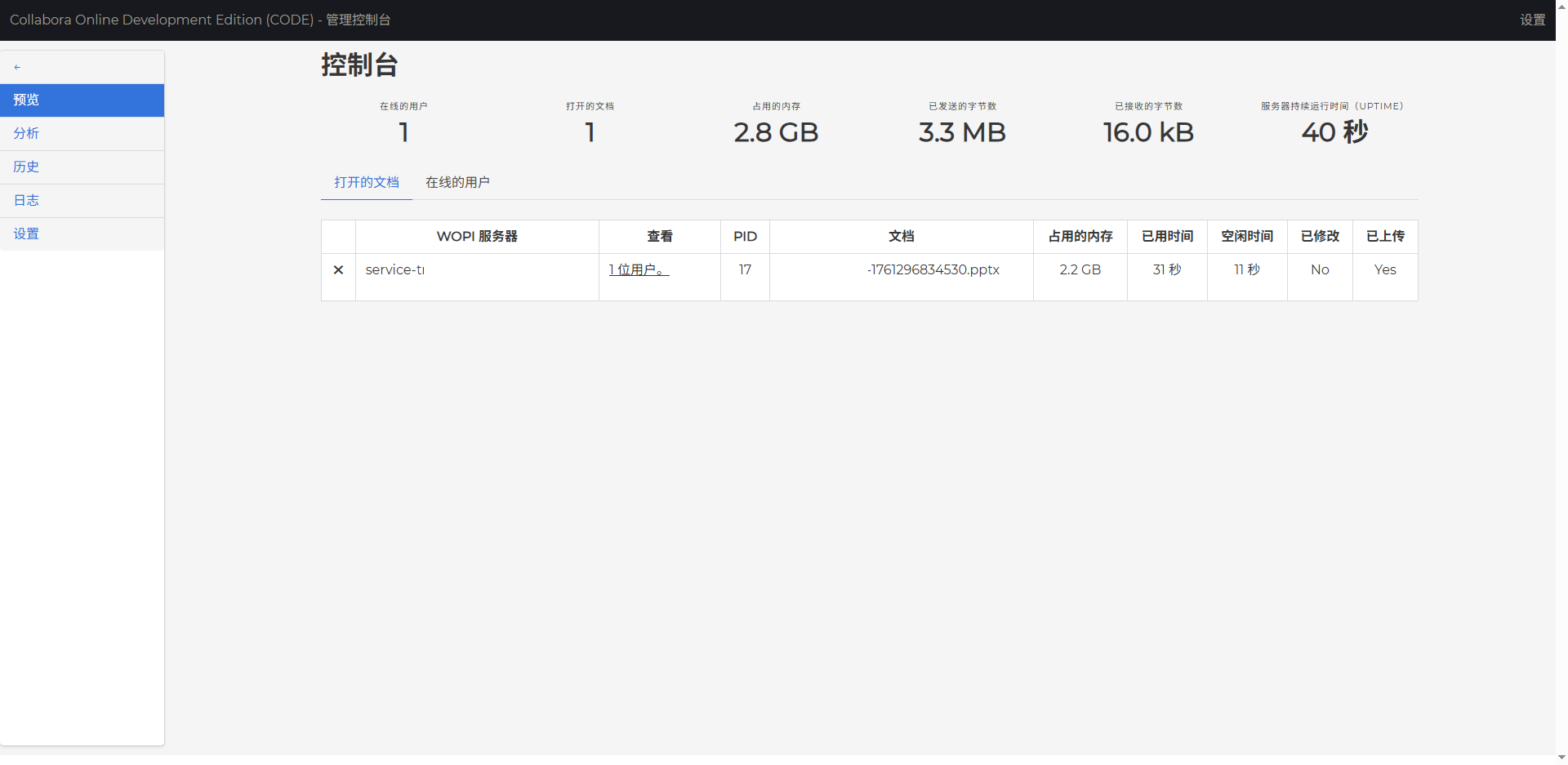
插个题外话,此时我真的很无奈,不过也有一丝新奇,Collabora 里打开一份 4.09 MB 大小的 PPT 竟然要占用 2 个多 G 的内存?
更新测试环境
随后我又进行了各种折腾尝试,增加断开自动重连,补充日志打印等。一转眼就到了 17:00,测试环境可以准备进行更新了(CI/CD 取消后,目前的测试环境更新非常耗时,动则半小时准备)。
不出所料,没有意外,问题依然存在。
Collabora 服务重启及内存调整
不行了,这种情况还是要反馈到当前项目技术经理,看看怎么处理。
我把问题,排查过程和一些思考及截图都发给了领导,领导先确认了下情况,也问了问有没有和“前任”沟通过。
还问了问我 Collabora 服务运行了多长时间了,重启或加点内存试试。
我检查了下,运行 27 天,服务配置最大 2C2G。
此时,我已经感觉有些不对劲了,脑海里闪过两个片段:同一份 PPT 文件,测试环境 Collabora 控制台显示内存占用似乎一直都是几百 MB;我本地测试时,同一份 PPT 文件要占用 2 个多 G 内存。

我首先尝试了重启 Collabora 服务,没用。也幸好没用,不然还得排查是否要定时处理些东西。
接着,我尝试将服务内存配置从 2GB 增加到 4GB,K8s 提示可分配内存不够,只能先试试调到 3GB。
调好后,复测,好了!
我...,打开客户群,@客户,有空试试。
总结
一个问题,查了一天。
最简单的重启和调内存配置,竟然在得到提示前一直没有正式出现在我脑子里。过多关注了websocket 客户端,因为不熟悉 Collabora 简单搜索了下就搁置了。
一直开玩笑的“不行就重启,再不行就换机器”,这类修复技巧还是应该单独拎出来一定要去尝试的,尤其是:重启。
问题只是告一段落,至于后续的此问题调整计划我就不细赘述了。